LLMO / GEO と md サブドメインの基本概念
「なぜサイト本体に手を加えず、AI 向けに別ドメインで Markdown を出すのか」を理解するための章です。 このプラグインの設計判断はすべて、AI 検索時代に従来 SEO を壊さずに最適化するという目的から導かれています。
LLMO / GEO とは
定義
LLMO (Large Language Model Optimization) および GEO (Generative Engine Optimization) は、 ChatGPT / Claude / Perplexity / Gemini といった生成 AI を裏で動かす検索体験のために、 自社サイトの情報をどう露出させるか・どう正確に拾わせるかを最適化する考え方です。 言い換えれば、「Google for Humans」 から 「Engines for AIs」 へ最適化対象が広がった ことを指します。
SEO との違い
| 観点 | 従来 SEO | LLMO / GEO |
|---|---|---|
| 主な読者 | 人間 + 検索エンジンクローラ (Googlebot / Bingbot) | AI クローラ (GPTBot / ClaudeBot / PerplexityBot 等) + 生成 AI のリトリーブパイプライン |
| 結果画面 | 10 個の青リンク (SERP) | AI が自然言語で要約 + 引用元リンク |
| 主要な指標 | 順位 / CTR / 表示回数 | 引用される確率 / 引用文の正確性 / ブランド名の出現頻度 |
| 最適化対象 | HTML / meta / JSON-LD / 内部リンク構造 | token 効率の良いコンテンツ / 構造化された自然言語 / 引用しやすい段落構造 |
| クローラへの優しさ | HTML 全体をパースしてもらう前提 | 必要最小限の情報量で意味が伝わる前提 (token 課金時代) |
AI 検索エンジンの挙動
ChatGPT・Claude・Perplexity・Gemini 等の生成 AI は、内部的には次のような流れで Web 上の情報を扱います。
- クロール: 専用 bot (例:
GPTBot,ClaudeBot,PerplexityBot,Google-Extended) が Web を巡回し、テキスト本文を取得する - 埋め込み (embedding): 取得したテキストをベクトル化してインデックスに格納する
- リトリーブ: ユーザの質問に意味的に近い断片を取り出す
- 生成: 大規模言語モデルに「質問 + 取り出した断片」を渡し、要約 / 回答 / 引用を生成する
このパイプラインで重要なのは、「取得段階で本文と構造を AI に渡しやすい形にしておく」 ことです。
HTML をそのままパースさせると <div class=...> や JavaScript / CSS のノイズで token を浪費し、
意味を取り違えるリスクが上がります。Markdown 並行版を提供することで、この浪費を取り除けます。
補足
AI クローラへのアクセス制御は robots.txt での User-agent 別許可 / 拒否でも可能ですが、
それは「弾く」or「弾かない」の二値しかなく、渡す内容そのものを最適化する ことはできません。
LLMO / GEO のアプローチは「弾かないなら、渡し方も最適化しよう」という発想です。
なぜ Markdown なのか
「AI 向けにコンテンツを最適化する」と言ったとき、技術的選択肢は複数あります。 このプラグインが Markdown を採用した理由を整理します。
token 効率
生成 AI のコンテキストウィンドウは有限であり、API 課金もトークン単位です。
同じ「H1 タイトル + 本文 + リスト」を表現するときの長さを比較すると、
一般に HTML > Markdown です。HTML は <p class="entry-content">...</p> のようにタグや属性が大量に挟まりますが、
Markdown は # タイトル + 本文の最小構文に圧縮できます。
このプラグインの実装でも、nav / aside / footer /
script / style / form / iframe /
noscript / svg / canvas 等のタグは
md-renderer.php 内で 完全除外 され、本文系のみ Markdown 化されます。
これは ksmd_render_node() 内のホワイトリスト方式で実装されています。
ノイズ削減
HTML テーマには次のような AI にとってのノイズが含まれがちです。
- サイト全体ナビゲーション (
<nav>)、フッター (<footer>)、サイドバー (<aside>) - JavaScript の inline コード (
<script>) - 装飾用のラッパ
<div class="entry-meta">など - SNS 共有ボタンのフォーム (
<form>) - Cookie 同意バナー、ポップアップ広告
これらは人間にとっては有益ですが、AI が「本文を理解する」目的では雑音です。 Markdown 並行版は 本文 + 引用 + リスト + 見出し + リンク + 画像 だけを残し、 それ以外を取り除いた状態を AI に渡します。
構造化されたコンテンツ
Markdown は単なる「軽い」テキスト形式ではなく、意味構造を持つテキスト です。
#〜###### の見出しレベル、- / 1. のリスト、
> の引用、** / * の強調、リンク・画像の構文、
これらは AI が文書構造を理解する手がかりとして機能します。
変換ルール (実装の概要)
実プラグインの includes/md-renderer.php では、the_content フィルタを通過した HTML を DOMDocument でパースし、
ホワイトリスト方式で次のように Markdown に変換しています。
| HTML | Markdown |
|---|---|
<h1> 〜 <h6> | # 〜 ###### |
<p> | 段落 (空行で区切る) |
<ul><li> | - item |
<ol><li> | 1. item |
<a href="x">y</a> | [y](<x>) (CommonMark angle-bracket link) |
<strong> / <b> | **y** |
<em> / <i> | *y* |
<blockquote> | > y |
<pre><code class="language-php"> | |
<img alt="a" src="s"> |  |
<hr> | --- |
リンク URL に ( や ) が含まれる場合 (例: Wikipedia 記事の Foo_(bar)) でも壊れないよう、
URL は < > で囲む CommonMark 仕様に準拠しています。
💡 ポイント
the_content フィルタを通すため、ショートコード展開・キャプション処理・段落自動補完など、
テーマ・他プラグインが本文に対して行う加工は そのまま反映されてから Markdown 化 されます。
ただし、md 経路では oEmbed の autoembed と wp_filter_content_tags は一時的に外して安全性を確保しています。
md サブドメインの設計思想
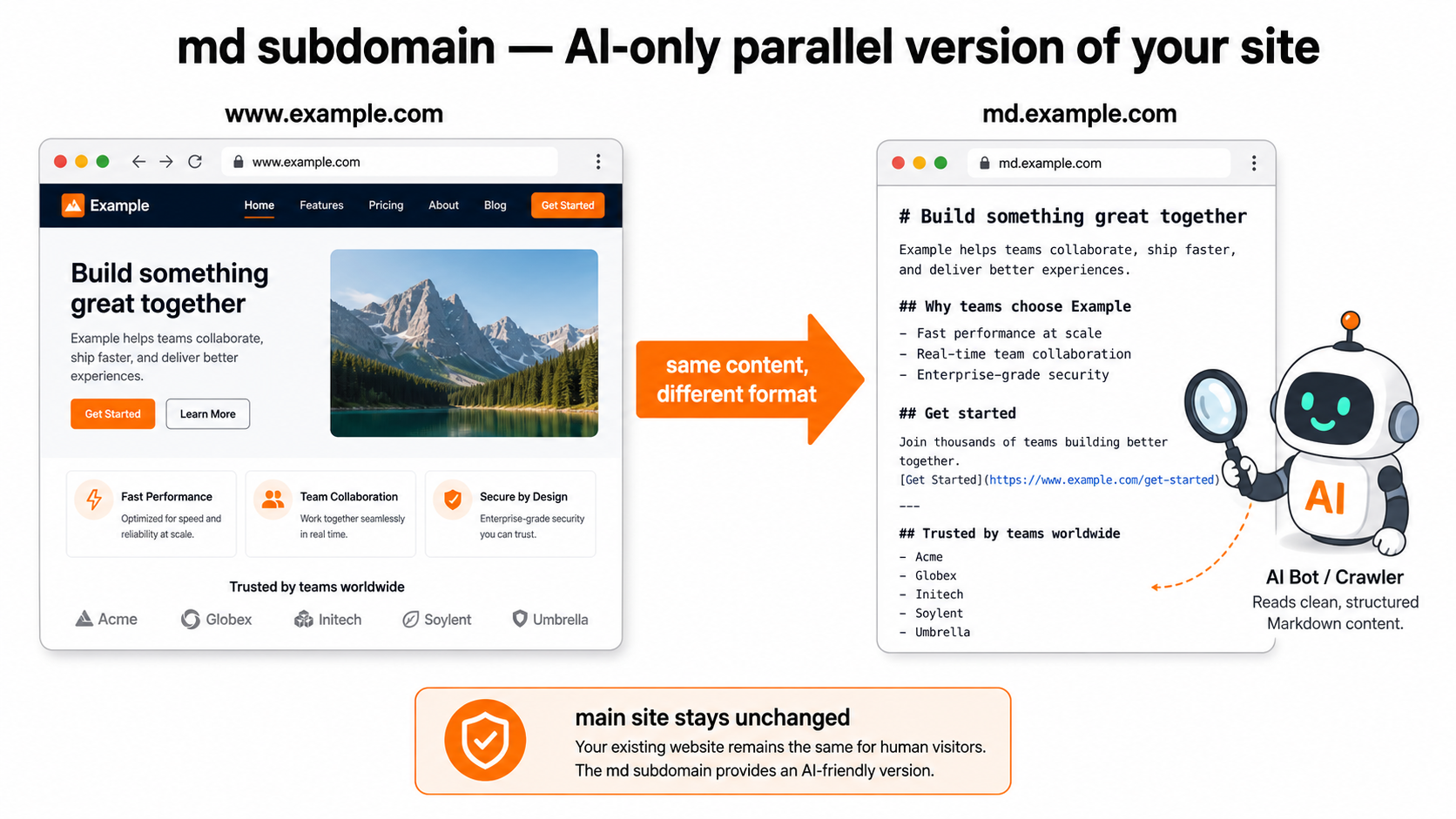
なぜ別ドメインなのか
「同じサイトで ?format=md をつけたら Markdown を返す」「/wp-json/... に Markdown エンドポイントを足す」といった、サブドメインを使わないアプローチもあり得ます。
このプラグインがそれらではなく サブドメイン分離 を選んだ理由は次の通りです。
- SEO 上の主従宣言が明確: 別ホストにすることで、HTTP
Link: rel="canonical"ヘッダで「主は www」と明示しやすい - キャッシュ戦略が独立: Cloudflare 等のエッジキャッシュ・WAF・bot ルールを md ホストにだけ適用できる
- 管理が分離: Search Console や AI ボット管理ダッシュボードで md を別プロパティとして登録できる
- 影響範囲が物理的に隔離: 万一プラグインの動作が暴走しても、メインサイト (www) のリクエストは
HTTP_HOST不一致で完全に no-op となり影響を受けない - 既存 SEO プラグインと無干渉: Yoast / RankMath が出力する canonical / OGP / JSON-LD は www のページにそのまま残り、md はそれらを「指す」立場に徹する
メインサイト無改変の徹底
実コードの includes/core-functions.php 冒頭の ksmd_handle_subdomain_request() は次のような構造になっています (実体)。
add_action( 'template_redirect', 'ksmd_handle_subdomain_request', -1 );
function ksmd_handle_subdomain_request() {
// (1) host 判定 — md ホスト以外は no-op (メインに副作用ゼロ)
$host = isset( $_SERVER['HTTP_HOST'] )
? strtolower( wp_unslash( $_SERVER['HTTP_HOST'] ) )
: '';
$opts = get_option( KSMD_OPTION_KEY, array() );
$default_md_host = ksmd_default_md_host();
$md_host = isset( $opts['md_host'] ) && $opts['md_host'] !== ''
? $opts['md_host']
: $default_md_host;
$md_host = apply_filters( 'ksmd_host', $md_host );
if ( $host !== strtolower( (string) $md_host ) ) {
return; // メイン側は完全に no-op
}
// ... ここから先は md ホストのリクエスト処理 ...
}
template_redirect の priority -1 で動作するため、既存テーマやプラグインの priority 1 以上のフックよりも先に実行されますが、
md ホスト以外では即 return する ため、メインサイトの出力フローには 1 ms 以下の影響しかありません。
例外: メイン側 alt-link (HTTP ヘッダ + <head> 内 <link> タグ)
「メインサイト無改変」の境界線上にある機能として alt-link (includes/md-alternate-link.php) があります。
これはメインサイトの HTML レスポンスに HTTP Link: rel="alternate"; type="text/markdown" ヘッダ + HTML <head> 内の対応 <link> タグを追加し、AI クローラに md 並行版の存在を発見させる機能です。
- HTML body には一切書き込まない (人間ユーザーへの視覚ノイズなし、テーマ・他プラグインのレンダリング非干渉)
- HTTP ヘッダ追加 +
<head>内<link>タグの 2 経路のみ (取りこぼし防止のため両出し) - 設定 toggle (
enable_md_alternate_link) で OFF 可能 — 厳格に「HTTP レスポンス全体非改変」を求める運用は OFF に設定する - デフォルト ON。「対象範囲」タブで OFF にされた post_type / route には出力しない (md 側 resolver と整合)
この設計は「メイン側 HTML body 改変ゼロ」を厳守しつつ、AI クローラ向けの discovery 経路を 1 つ増やすトレードオフです。 HTTP レスポンス全体を完全に従来どおりにしたい場合は本機能を OFF にしてください (md ホストの favicon proxy も同様に設定 toggle で OFF 可能)。
サブディレモード (root インデックス配信、v1.0.3)
WordPress 本体が サブディレクトリインストール されているサイト (例: example.com/wp/ に WP がある) では、md サブドメイン側の root (https://md.example.com/) にアクセスしたときに、WP の home_path (/wp) と URI (/) が一致しないため、resolver が 404 にフォールバックします。これは「並行版」原則と矛盾するため、v1.0.3 で サブディレモード という専用の short-circuit を導入しました。
- default OFF。WP がルート install (
example.com/) の標準環境では発動せず、従来挙動を維持。 - 有効化したサブディレ環境では、md ホスト root に auto モード (subdir 専用 renderer でサイト概要・最近の記事一覧・sitemap.xml 誘導・メインサイトリンクを自動生成) または custom モード (ユーザ編集 Markdown、最大 256KB) を配信。
- auto モードの canonical はメインサイトの WP ルート (
home_url('/')) を指す。custom モードでは canonical を出さない (該当ページがメインサイトに存在しない可能性が高いため)。 - 並行版原則は維持される: auto モードは「このドメインは {parent} の Markdown 並行版」であることを冒頭の Schema.org/WebSite ブロックで明示宣言する。
詳細は 出力タブ — サブディレモード を参照。
「別ドメインで AI 専用版を提供する」 = 並行版という哲学
md サブドメインのページは、コンテンツ的にはメインサイトの「並行版 (parallel version)」 です。 記事数・URL 構造・タイトル・本文・著者・日時はメインと同じものを参照し、表現フォーマットだけが Markdown に置き換わります。 意図的にコンテンツを変えたり、AI 専用の追加情報を出したりはしません (用途に応じて拡張フィルタで追加は可能)。 これにより以下の効果が得られます。
- メイン側に新しい記事を出すと、md 側にも自動的に反映される (運用作業の二重化なし)
- メイン側を非公開化・パスワード保護・下書きに戻すと、md 側も自動的に 404 になる (security.php の
ksmd_is_post_publicly_serviceable()で実装) - 「md 側だけで誤ってコンテンツが残る」事故が起きない
LLM ネイティブ Markdown インライン Schema.org 記法
LLM ネイティブサブドメインという考え方
柏崎剛が提唱する LLM ネイティブサブドメイン では、Schema.org の構造化データを JSON-LD ではなく Markdown のインライン引用ブロックとして埋め込む アプローチを採用します。 本プラグインはこの考え方を実装したものです。
記法の例
実際にこのプラグインが出力する Markdown の冒頭ブロックは次のような形になります (実装は md-schema-mapper.php)。
# 記事のタイトル
> **Canonical:** https://example.com/articles/foo
> This Markdown is the AI-optimized parallel version of the canonical HTML page above. Authority, freshness, and canonicalness belong to the canonical page.
> **Schema.org/Article**
> - headline: 記事のタイトル
> - author: 山田太郎
> - datePublished: 2026-04-30T09:00:00+00:00
> - dateModified: 2026-04-30T09:00:00+00:00
> - inLanguage: ja
> - url: https://example.com/articles/foo
>
> **Schema.org/BreadcrumbList**
> - 1: サイト名 (https://md.example.com/)
> - 2: 記事一覧 (https://md.example.com/articles/)
> - 3: 記事のタイトル (https://md.example.com/articles/foo/)
(本文)
---
> **Schema.org/Person** (author)
> - name: 山田太郎
> - url: https://example.com/author/yamada/
>
> **Schema.org/Organization** (site owner)
> - name: サイト名
> - url: https://example.com/
> - logo: https://example.com/wp-content/uploads/.../logo.png
なぜインラインなのか (JSON-LD との比較)
| 観点 | JSON-LD (従来) | Markdown インライン Schema.org |
|---|---|---|
| 埋め込み位置 | <script type="application/ld+json"> ブロックとして HTML head/body に分離 |
本文 Markdown と同一文書、見出しの直後の引用ブロック |
| パースの容易さ | JSON パーサが必要、コンテンツとは別の文脈 | テキストとして読める、LLM が自然言語と一体で処理できる |
| LLM のアテンション | ページ全体に分散 | 冒頭の引用ブロックに集中 (lost-in-the-middle 問題の回避) |
| token 効率 | キー名 ("@context", "@type", "@id") を毎回記述 |
シンプルな > - key: value 形式 |
| 運用 | 本文と構造データを分離管理 | 本文と構造データが同じドキュメントとして可視化 |
LLM のアテンションは文書冒頭に強く偏る (lost-in-the-middle 問題) ことが知られているため、 このプラグインは Schema header を必ず H1 直後に配置します。 JSON-LD のように HTML 末尾や別 script タグに置く方式と比べ、AI が確実に拾える位置に構造データを置けるのが利点です。
design memo
JSON-LD と Markdown インラインは併置しません (R1-R5 三者協議で確定)。 並行配信なので「もし JSON-LD が必要なら www 側で出ている」前提に立ちます。 md 側で重ねるとトークンの無駄になるためです。
Canonical の扱い
主従関係の 3 層宣言
このプラグインは 「md は seo (www) の補助、md は seo を AI に理解させるための並行版」 という主従関係を、3 つの層で一貫して宣言します。
| 層 | 宣言場所 | 宣言内容 |
|---|---|---|
| HTTP | Link ヘッダ |
Link: <https://example.com/articles/foo>; rel="canonical" |
| Markdown 本文 | H1 直後の blockquote | > **Canonical:** https://example.com/articles/foo |
| Schema.org | Article / WebPage の url |
> - url: https://example.com/articles/foo |
authority / freshness / canonicalness は seo に帰属
上記 3 層の宣言で、AI クローラには次のメッセージが伝わります。
- authority (権威): 引用元として参照すべき URL は seo (www) 側
- freshness (鮮度): 最終更新日時の真の場所は seo 側 (md は parallel version)
- canonicalness (正規性): 同一コンテンツが複数 URL で見つかった場合の真の URL は seo 側
この設計のおかげで、AI が記事を引用する際にユーザに見せる URL は md ではなく www 側になることが期待できます。 つまり、AI からの参照トラフィックは引き続き既存の www にやってきます。
md→md 内部巡回完結
一方で、AI クローラが md ホスト内のリンクを辿って関連記事をクロールするときは、
md 内のリンクは md_host のまま にしてあります (実装は ksmd_rewrite_url_to_md())。
これは「md 内ではナビゲーション完結性」を保ちながら、構造データ (Article.url, Person.url, Organization.url) では seo を指すという二重戦略です。
BreadcrumbList の URL はナビゲーション情報なので md_host を維持し、
Article / WebPage / Person / Organization の url フィールドは seo を指す、という使い分けです。
この設計は md-schema-mapper.php の ksmd_schema_header_block() / ksmd_schema_footer_block() で実装されています。
💡 補足
md ホストの全レスポンスには X-Robots-Tag: noindex, follow も付くため、Google・Bing 等の通常検索エンジンに md がインデックスされてしまうことを二重に防ぎます。
「noindex, follow」 なので md 内のリンクは辿られますが、md 自身は検索結果に出ません。
対応する AI クローラ
このプラグインは bot を弾くロジックを持っていません (旧 P7 で実装した UA allowlist は LLMO/GEO の趣旨と矛盾するため削除済み)。 よって md ホストにアクセスできる全クローラに Markdown を返却 します。 想定する主な AI クローラは以下の通りです。
| 運営 | User-Agent (一例) | 用途 |
|---|---|---|
| OpenAI | GPTBot/1.x, ChatGPT-User/1.x, OAI-SearchBot/1.x |
ChatGPT のリトリーブ・SearchGPT のインデックス・モデル学習用クロール |
| Anthropic | ClaudeBot/1.x, Claude-Web/1.x, anthropic-ai |
Claude / Claude.ai のリトリーブ用クロール |
| Perplexity | PerplexityBot/1.x, Perplexity-User |
Perplexity 検索のリアルタイム引用クロール |
Google-Extended, GoogleOther, Googlebot |
Gemini モデル学習・SGE / AI Overviews 用 (Google-Extended)、通常検索 (Googlebot) | |
| Microsoft | bingbot, BingPreview |
Bing Chat / Copilot 用 |
| Apple | Applebot, Applebot-Extended |
Spotlight・Siri・Apple Intelligence 学習用 |
| Meta | FacebookBot, Meta-ExternalAgent |
Llama 系モデル用 |
| その他 | YouBot, cohere-ai, Diffbot, CCBot 等 |
Common Crawl 系 / 各社 AI 検索 / モデル学習用 |
各クローラの違い
- 学習目的のクローラ (例:
GPTBot,ClaudeBot): モデル訓練データ収集が目的、頻度は中〜低 - リアルタイム検索のクローラ (例:
OAI-SearchBot,PerplexityBot): ユーザの質問にその場で引用を返すための即時クロール、頻度は高 - ユーザエージェント (例:
ChatGPT-User): ユーザが「このページを読んで要約して」と指示したときの代理クロール、フットプリントは小さい
アクセスログでの観測
このプラグインは「観測専用」のアクセスログ機能を備えています (デフォルト OFF、diagnostics タブで有効化)。
ログは何も弾かず、来訪 bot の User-Agent / URI / ステータス / 応答時間を専用テーブル {prefix}ksmd_access_logs に記録するだけ です。
「実際にどの bot が、どの記事に、どのくらいの頻度で来ているか」を観測するための情報源として使ってください。
悪質トラフィックの遮断は Cloudflare / WAF / DDoS L7 等の上位レイヤに任せる方針です。
kill switch / master switch とは
このプラグインには「動かす / 動かさない」を切り替えるトグルが 2 種類あります。それぞれ役割が異なります。
master switch (enabled)
- 「一般」タブの「プラグインを有効化」チェックボックス
- default は OFF (インストール直後の事故防止)
- OFF のとき: md サブドメインへのリクエストには
HTTP 503 Service Unavailable+ 「プラグインがまだ有効化されていません」 を返す - ON のとき: md サブドメインで Markdown を配信開始
master switch は「設定を全部終わらせて、確認してから動かしたい」というユーザの意思を表すスイッチです。 プラグインを WordPress に有効化しただけでは何も配信されないため、「設定中の中途半端な状態が AI クローラに見られる」事故が起きません。
kill switch
- 「一般」タブの 🛑 kill switch ボタン (master switch とは別の操作)
- default は OFF
- ON にすると md サブドメインのリクエストには
HTTP 503 Service Unavailable+ 「md サブドメインは一時停止中です」 を返す - 同時にすべての ksmd 系キャッシュ (transient / object cache / 専用テーブル) をフラッシュ
- メインサイト (www) には一切影響しない
kill switch は「何か問題が起きた、ひとまず止めたい」緊急時のためのスイッチです。 master switch と違い、トグルしただけでキャッシュ全消去まで行うので、「キャッシュに残った古い出力が表示され続ける」リスクを排除 できます。
使い分け
| 状況 | 使うスイッチ |
|---|---|
| 初期セットアップ完了前 (まだ AI に見せたくない) | master switch を OFF のままにしておく (インストール直後の状態) |
| 運用中だが、何か出力がおかしい / 一時的に止めたい | kill switch を ON |
| 長期メンテナンスのためプラグインごと無効化 | WordPress 管理画面でプラグインを停止 |
| 「やっぱり AI 向け配信を当面しない」と決めたとき | master switch を OFF |
⚠ 注意
どちらのスイッチも、メインサイト (www) のリクエストには 絶対に影響しません。
HTTP_HOST 判定のあとでスイッチを評価するためです。
逆に、md ホスト用 index.php が存在しない (Bootstrap installer 未実行) 場合は、
スイッチ以前に WordPress に到達できず DNS / 404 エラーになります。
主要な用語集
本マニュアルおよび設定画面で頻出する用語の定義です。設定タブ編・応用編を読む前に一度通読することをおすすめします。
md ホスト (md_host)
このプラグインが Markdown を配信するために使う専用サブドメインのホスト名 (例: md.example.com)。
設定の md_host で保持され、get_option(KSMD_OPTION_KEY)['md_host'] から参照されます。
空欄の場合は home_url() から「md. + 主ホスト (www. 除去後)」が自動算出されます (ksmd_default_md_host() 関数)。
ksmd_host filter で外部から書き換え可能です。
seo ホスト (seo_host)
メインサイトのホスト (例: example.com や www.example.com)。
このマニュアルでは「メインホスト」「www 側」「正規ページ」「seo」 と同義で使います。
プラグイン用語としては「home_url() から得られるホスト」を指します。
canonical
Web 上で同一コンテンツが複数 URL に存在するときに「真の URL はこれだ」を宣言する仕組み。
このプラグインの md 出力は HTTP Link: rel="canonical" ヘッダ + Markdown 冒頭 blockquote + Schema.org の url フィールドの 3 層で seo (www) URL を canonical として指します。
Schema.org type
Schema.org が定義するコンテンツ種別 (Article, WebPage, Service, Product,
Event, JobPosting, FAQPage, HowTo, ProfilePage,
CollectionPage, SearchResultsPage 等)。
このプラグインは post_type / route ごとに type をマッピングできます (default 値は ksmd_get_default_settings() の schema_type_map に定義)。
個別投稿で上書きしたい場合は ksmd_schema_type filter を使います。
inLanguage
Schema.org の inLanguage プロパティ。BCP 47 形式 (ja, en-US 等) で言語を表す。
このプラグインは default で get_locale() から自動算出 (_ を - に置換)、設定タブ「言語」で明示指定も可能です。
route
URL の種類 (singular ではなく一覧系)。プラグイン内で扱う route は次の 10 種類:
archive / term / category / tag /
author / date / home / front_page /
search / feed。
それぞれ「対象範囲」タブで個別に ON/OFF できます。
post_type
WordPress のコンテンツ種別 (post, page, または CPT)。
このプラグインは get_post_types(['public' => true]) で全 public post_type を自動列挙し (ただし attachment は default 除外)、
「対象範囲」タブで個別に ON/OFF できます。
master switch / kill switch
前章「kill switch / master switch とは」 を参照。 前者は通常 ON/OFF、後者は緊急停止 + キャッシュフラッシュ。
Bootstrap installer
md サブドメインのドキュメントルートに、メイン WordPress の wp-blog-header.php へ橋渡しする
index.php を SSH なしで自動生成する診断タブの機能。
「兄弟構成」(例: /wp/ と /md/ が /var/www/ 直下に並ぶ) と
「ABSPATH 直下サブディレクトリ構成」(例: /var/www/wp/ 内に /var/www/wp/md/ がある、XServer 標準) の 2 種類をサポート。
実装は includes/md-bootstrap-installer.php、UI は「診断」タブ。
option key / option migration
このプラグインは設定を wp_options テーブルの ksmd_settings という 1 つのキーにまとめて保存します
(定数 KSMD_OPTION_KEY)。
旧バージョンの kashiwazaki_llmo_md_settings から自動マイグレーションされます (ksmd_migrate_legacy_option())。
cache key / cache backend
cache key は 'ksmd_md_' . md5($cache_uri) の形式。検索ルートでは ?s= も含めた md5 を付加します。
cache backend は 3 種類: transient (default、wp_options 利用)、object_cache (Redis / Memcached / W3TC 等)、custom_table (専用テーブル {prefix}ksmd_cache)。
HMAC test token
診断タブの Test renderer で「ログイン中の admin の操作」を md ホストに伝えるための cookieless トークン。
wp_salt('nonce') を共有秘密として HMAC-SHA256 で署名され、5 分間有効。
md ホスト側では X-Ksmd-Test-Token ヘッダで受け取り、検証に成功するとキャッシュをバイパスして即時再生成します。
実装は security.php の ksmd_generate_test_token() / ksmd_verify_test_token()。
X-Ksmd-Cache ヘッダ
md ホストのレスポンスに必ず付くデバッグヘッダ。値は HIT / MISS / NO-CACHE のいずれか。
ブラウザの開発者ツールでネットワークタブを開けば、特定リクエストがキャッシュ由来か再生成かを確認できます。
403 / 503 / 404 の使い分け
- 503: master switch OFF または kill switch ON のとき (md ホストへの全リクエスト)
- 404: master switch ON でも、対象範囲タブで OFF の post_type / route や、存在しない URI、非公開投稿へのアクセス
- 403: このプラグイン自身は出さない (Cloudflare / WAF 経由なら出る可能性あり)
X-Robots-Tag: noindex, follow
md ホストの全 Markdown レスポンスに付与される HTTP ヘッダ。
noindex で「Google 等の検索結果には載せない」、follow で「内部リンクは辿ってよい」 を意味します。
これにより md ページがメイン側と重複コンテンツとして扱われるリスクを物理的に排除します。
Cache-Control: no-store
Cloudflare 等のエッジキャッシュでさらにキャッシュされてしまうことを防ぐためのヘッダ。 プラグイン内部 (transient / object cache / 専用テーブル) ではキャッシュするが、エッジレイヤではキャッシュさせない設計です。
この章のまとめ
- LLMO / GEO は AI 検索時代の SEO の拡張概念であり、最適化対象が「人間 + 従来検索」 から 「人間 + 従来検索 + AI クローラ」 に広がった
- このプラグインは サブドメイン分離 + Markdown 並行版 + Markdown インライン Schema.org 記法 の組み合わせで AI 向け最適化を実現する
- メインサイト (www) には一切手を加えず、HTTP_HOST 判定で md ホストのリクエストだけを処理する
- 主従関係は HTTP
Linkヘッダ・Markdown 冒頭 blockquote・Schema.org のurlフィールドの 3 層で seo (www) を canonical として宣言 - master switch / kill switch / Bootstrap installer などの安全機構が用意されている
ここまでの概念が腑に落ちたら、次章 5 分クイックスタート で実際に動かしてみましょう。